In my last post, we set up ZeroTier as a basic mesh VPN, allowing access to any nodes that joined the network via their ZeroTier IP addresses. In this post, we will set be setting up ZeroTier to allow us to access our own network from the wider internet.
Continuing my series of blog posts on VPNs, now we’re going to be installing the ZeroTier self hosted controller! Again we’ll be installing it on Debian 11, but the instructions should work for Debian 12 as well.
ZeroTier is a (VPN) and software-defined networking (SDN) platform in one that enables connectivity between devices and networks across the internet. It creates a virtual overlay network that allows devices to communicate as if they were connected to a physical network (LAN), regardless of their actual location. ZeroTier has many possible configurations, so in this post, we’ll just be configuring ZeroTier to allow remote access to a single node (in this post, the node will be the server that I’m installing it on). In later posts, we will walk through setting up ZeroTier in other configurations.
So a bit over a week after I couldn’t sleep, tossing and turning in bed when I first came up with the idea of ZeroTier-Console, the first release is ready for some field trials!
As an update to my old post – https://sirlagz.net/2016/01/20/live-resizing-lvm-on-linux/ – since utilites mature and change, tasks can get easier (or harder) as there are more commands and functionalities added.
In this instance, parted and lvm have been updated to make this a bit easier.
Step 1 – Resizing Hard Drive
This step remains the same. Expand the disk on your hypervisor, and if it doesn’t automatically update in the virtual machine itself, try running the following command # for x in /sys/class/scsi_disk/*; do echo '1' > $x/device/rescan; done
If the disk is still the same size in fdisk, then you’ll need to reboot the server.
Step 2 – Resizing Partition
Again we’ll need to use parted in this step, but the commands are a bit easier.
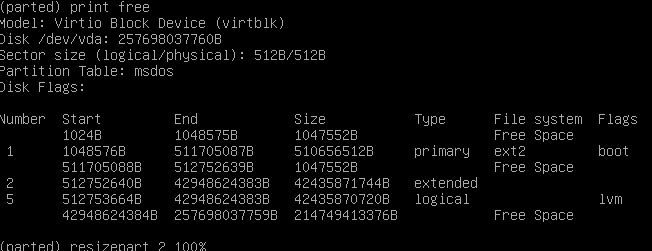
Run parted as root, and then run a print free command to make sure that you have space at the end of the partition.
You can see in my screenshot that my drive has some Free Space at the end
I need to resize both partitions 2 and 5 in my instance, but your situation may or may not be the same. Run the following commands to resize both partitions 2 and 5 to the maximum available space.
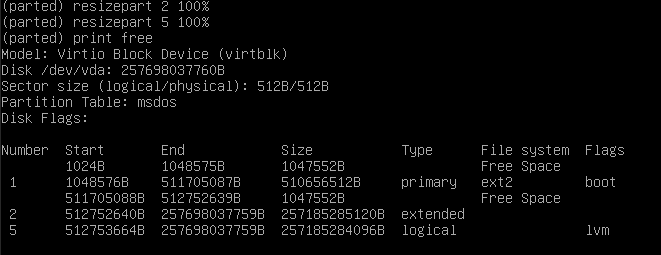
resizepart 2 100%
resizepart 5 100%
Now run print free again to verify that the partitions have been resized.
Run quit to exit parted.
Step 3 – Resizing Physical Volume
This is the same as before, do a pvresize to expand the physical volume to the maximum capacity. Make sure you’re specifying the correct partition.
pvrsize /dev/vda5
Step 4 – Resize Logical Volume and Filesystem
Now here is where it changes a bit. I don’t know when LVM got the ability to resize the filesystem as well (assuming it’s a filesystem that the utilities support. I use ext4 on most of my systems), but we can now resize everything in one go.
If you don’t know the path of your logical volume, you can check with the lvdisplay command
Run the lvresize command with the path to resize both the volume and filesystem in one go
lvresize -l +100%FREE -r /dev/VolGroup/lv_root
Now your filesystem will have been expanded to all available space on the disk.